Case study · 2024 to present
Scalable, cost-effective voice agents: a platform-based blueprint
A hierarchical voice-agent platform for a Fortune-5 healthcare buyer handling millions of daily customer interactions. A Master Agent orchestrates specialized SLM- and LLM-powered sub-agents; a tiered model strategy plus high-precision intent classification cut the theoretical tens-of-millions-of-LLM-calls-per-day workload by over 90%. Public co-authored blueprint on the CVS Health Tech Blog, Feb 2026.
Senior Forward Deployed Engineer · Co-author on the public blueprint
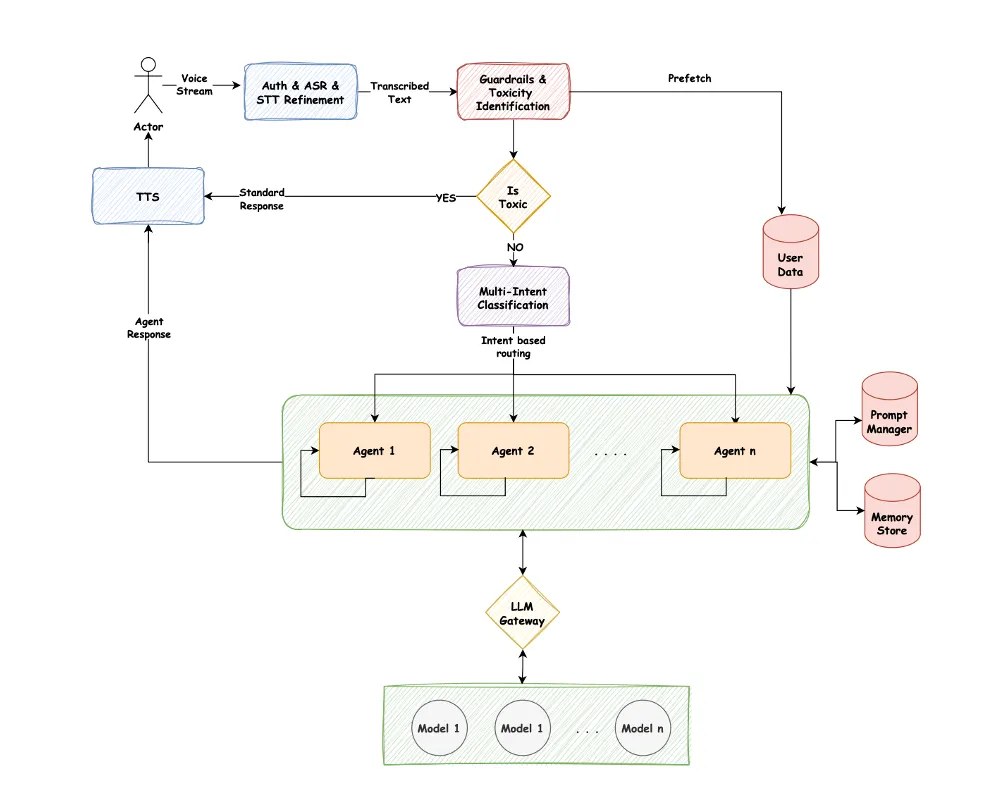
Stack
Python · LangGraph · BM25 (sparse retrieval) · Fine-tuned dense embeddings · ColBERT (late-interaction reranking) · SLMs + LLMs · Centralized LLM gateway · Active-active GPU infrastructure across two facilities · Enterprise prompt management platform
Outcomes
- Over 90% reduction in actual LLM usage vs. the theoretical peak of tens of millions of LLM calls per day.
- Intent classification weighted F1 of 0.86 via a four-stage multi-vector pipeline (BM25 sparse + dense + ColBERT late-interaction reranking).
- Auth-time pre-fetching cuts
prescription_statuslatency from ~1,200 ms to ~80 ms; 90 to 95% of typical requests served instantly from warm cache. - Geo-redundant active-active deployment across two facilities for zero-downtime operation.
- Public co-authored blueprint on the CVS Health Tech Blog (Feb 2026).
What I owned
One of the senior engineers on the platform team and a co-author on the public blueprint (seven-author byline). My center of gravity on this work was the intent-classification gatekeeper that the entire cost-optimization strategy hinges on, and the orchestration patterns the Master Agent uses to delegate to specialized sub-agents. The intent slice has its own deep dive in from IVR to agentic; the broader platform (telephony, GPU gateway, prompt management, geo-redundant infrastructure) was the work of the full team listed on the blueprint.
What shipped
A platform, not a bot. The architecture is a hierarchical agent system:
- A Master Agent that receives a classified intent and routes to the most efficient downstream system or sub-agent.
- A tiered model strategy: simple, high-volume tasks go to deterministic rules or fast SLM-powered sub-agents; only the most complex multi-turn conversations escalate to LLM-powered sub-agents.
- A high-precision intent classification gatekeeper that prevents simple queries from being misrouted into expensive LLM flows.
The composition is the point. No single layer reaches the 90% reduction; the layers stack, and the gatekeeper is the keystone.
The cost story
The headline economic claim is the >90% reduction in actual LLM usage. The path:
- Tiered models. The Master Agent sends the majority of queries to SLMs or deterministic rules. Most calls never see an LLM.
- Precision intent classification. Misroutes are the silent failure mode; an SLM-routable query that gets escalated to an LLM by mistake costs you on both ends. High weighted F1 (0.86) keeps that escalation rate low.
- Contextual efficiency. Auth-time pre-fetching and well-engineered prompts collapse the turn count for the queries that do reach an LLM.
The result: tens of millions of theoretical LLM calls per day collapse to a few million actual model interactions, the vast majority of which are cheap.
Intent classification (the gatekeeper)
A four-stage multi-vector retrieval pipeline does the routing:
- BM25 sparse retrieval as the lexical baseline.
- A fine-tuned dense encoder for semantic recall.
- ColBERT late-interaction reranking over the merged top candidates.
- An LLM at the end as the final classifier and out-of-scope filter, given only the top-K survivors.
Weighted F1 of 0.86 across the production intent set. The LLM is the most expensive node, so it is pushed to the end of the pipeline, where it adjudicates a small candidate set rather than acting as the primary classifier. The deep dive on this slice, including the synthetic-data pipeline and the multi-vector wiring in Qdrant, is in from IVR to agentic.
Auth-time pre-fetching
Customer authentication is a hard latency floor: the system has to verify identity before answering anything sensitive. The platform turns that window into useful work. While the customer is being authenticated, the system fetches their likely-needed user data and loads it into a high-speed cache. By the time the conversation begins, 90 to 95% of typical requests are answerable from warm cache. The published example is prescription_status, which drops from ~1,200 ms (cold) to ~80 ms (warm). The same pattern applies across intents that need user-scoped data.
Reliability posture
Voice agents at this scale are critical infrastructure, not experimental projects. The blueprint emphasizes the unglamorous half of the work:
- Active-active deployment across two geographically distinct facilities. No single points of failure on the GPU and gateway layer.
- Graceful degradation. SLM-powered and rule-based services keep operating if the LLM tier degrades.
- Centralized LLM gateway for budget controls, identity-integrated access, routing, rate limiting, and provider failover.
- Enterprise prompt management with versioning, audit logs, approval workflows, and a staging environment that mirrors production.
- Zero-downtime deployments via blue-green and canary releases.
Lessons
- Voice at enterprise scale is an infrastructure problem first, an AI problem second. The economics fall apart if you treat the LLM as the default and try to optimize around it; they work when you treat the LLM as the exception and let cheap, deterministic, or small-model paths handle the majority.
- The cost optimizer is high-precision intent classification. Get it wrong and every other layer is forced to escalate. Get it right and most of your traffic never sees an LLM.
- The auth window is free latency. Pre-fetching during a step the customer is already waiting on is the kind of unglamorous engineering that recovers an order of magnitude on the critical path.
- Platforms beat bots. The decoupled-layers architecture (telephony / runtime / orchestration / models / gateway) is what makes the blueprint replicable. The win is not a smart bot; it is the boring discipline of letting feature teams spend their time on the conversation, not the plumbing.